
metadata
tags:
- mmeb
- transformers
language:
- en
- ar
- zh
- ko
- ru
- pl
- tr
- fr
library_name: transformers
license: mit
pipeline_tag: image-feature-extraction
mmE5-mllama-11b-instruct
mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data. Haonan Chen, Liang Wang, Nan Yang, Yutao Zhu, Ziliang Zhao, Furu Wei, Zhicheng Dou, arXiv 2025
This model is trained based on Llama-3.2-11B-Vision.
Train/Eval Data
- Train data: https://huggingface.co/datasets/intfloat/mmE5-MMEB-hardneg, https://huggingface.co/datasets/intfloat/mmE5-synthetic
- Eval data: https://huggingface.co/datasets/TIGER-Lab/MMEB-eval, https://huggingface.co/datasets/Haon-Chen/XTD-10
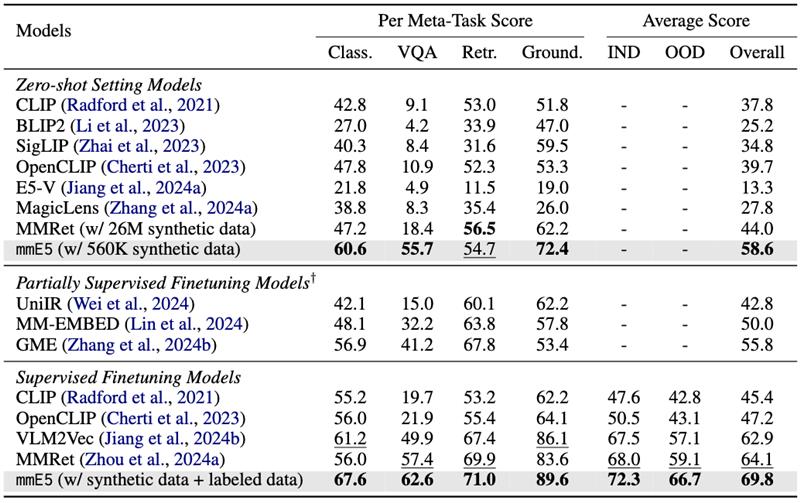
Experimental Results
Our model achieves SOTA performance on MMEB benchmark.
Usage
Below is an example we adapted from VLM2Vec.
First clone github
git clone https://github.com/haon-chen/mmE5.git
pip install -r requirements.txt
Then you can enter the directory to run the following command.
from src.model import MMEBModel
from src.arguments import ModelArguments
from src.utils import load_processor
import torch
from transformers import HfArgumentParser, AutoProcessor
from PIL import Image
import numpy as np
model_args = ModelArguments(
model_name='intfloat/mmE5-mllama-11b-instruct',
pooling='last',
normalize=True,
model_backbone='mllama')
processor = load_processor(model_args)
model = MMEBModel.load(model_args)
model.eval()
model = model.to('cuda', dtype=torch.bfloat16)
# Image + Text -> Text
inputs = processor(text='<|image|><|begin_of_text|> Represent the given image with the following question: What is in the image', images=[Image.open(
'figures/example.jpg')], return_tensors="pt")
inputs = {key: value.to('cuda') for key, value in inputs.items()}
qry_output = model(qry=inputs)["qry_reps"]
string = 'A cat and a dog'
inputs = processor(text=string, return_tensors="pt")
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## A cat and a dog = tensor([[0.3965]], device='cuda:0', dtype=torch.bfloat16)
string = 'A cat and a tiger'
inputs = processor(text=string, return_tensors="pt")
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## A cat and a tiger = tensor([[0.3105]], device='cuda:0', dtype=torch.bfloat16)
# Text -> Image
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a dog.', return_tensors="pt")
inputs = {key: value.to('cuda') for key, value in inputs.items()}
qry_output = model(qry=inputs)["qry_reps"]
string = '<|image|><|begin_of_text|> Represent the given image.'
inputs = processor(text=string, images=[Image.open('figures/example.jpg')], return_tensors="pt")
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## <|image|><|begin_of_text|> Represent the given image. = tensor([[0.4219]], device='cuda:0', dtype=torch.bfloat16)
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a tiger.', return_tensors="pt")
inputs = {key: value.to('cuda') for key, value in inputs.items()}
qry_output = model(qry=inputs)["qry_reps"]
string = '<|image|><|begin_of_text|> Represent the given image.'
inputs = processor(text=string, images=[Image.open('figures/example.jpg')], return_tensors="pt")
inputs = {key: value.to('cuda') for key, value in inputs.items()}
tgt_output = model(tgt=inputs)["tgt_reps"]
print(string, '=', model.compute_similarity(qry_output, tgt_output))
## <|image|><|begin_of_text|> Represent the given image. = tensor([[0.3887]], device='cuda:0', dtype=torch.bfloat16)
Citation
@article{chen2025mmE5,
title={mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data},
author={Chen, Haonan and Wang, Liang and Yang, Nan and Zhu, Yutao and Zhao, Ziliang and Wei, Furu and Dou, Zhicheng},
journal={arXiv preprint arXiv:2502.08468},
year={2025}
}