
metadata
language: it
license: apache-2.0
widget:
- text: Il [MASK] ha chiesto revocarsi l'obbligo di pagamento
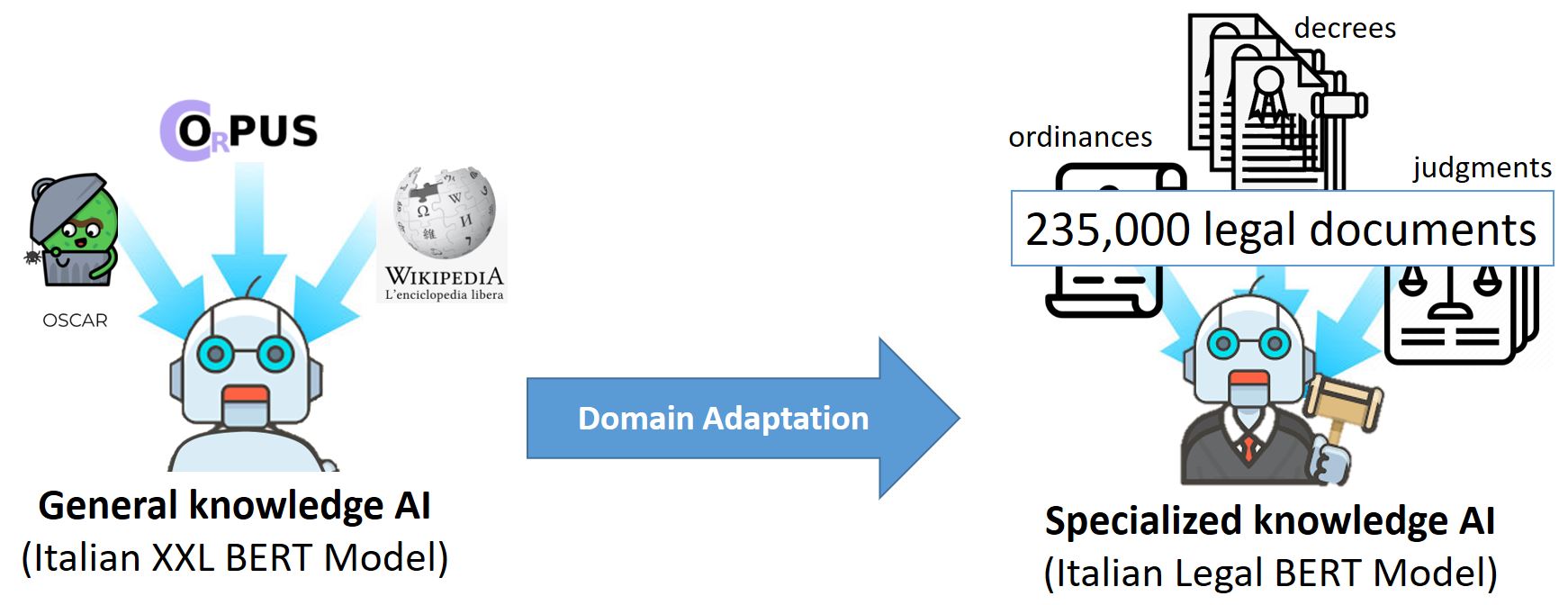
ITALIAN-LEGAL-BERT:A pre-trained Transformer Language Model for Italian Law
ITALIAN-LEGAL-BERT is based on bert-base-italian-xxl-cased with additional pre-training of the Italian BERT model on Italian civil law corpora. It achieves better results than the ‘general-purpose’ Italian BERT in different domain-specific tasks.
Training procedure
We initialized ITALIAN-LEGAL-BERT with ITALIAN XXL BERT and pretrained for an additional 4 epochs on 3.7 GB of preprocessed text from the National Jurisprudential Archive using the Huggingface PyTorch-Transformers library. We used BERT architecture with a language modeling head on top, AdamW Optimizer, initial learning rate 5e-5 (with linear learning rate decay, ends at 2.525e-9), sequence length 512, batch size 10 (imposed by GPU capacity), 8.4 million training steps, device 1*GPU V100 16GB
Usage
ITALIAN-LEGAL-BERT model can be loaded like:
from transformers import AutoModel, AutoTokenizer
model_name = "dlicari/Italian-Legal-BERT"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
You can use the Transformers library fill-mask pipeline to do inference with ITALIAN-LEGAL-BERT.
from transformers import pipeline
model_name = "dlicari/Italian-Legal-BERT"
fill_mask = pipeline("fill-mask", model_name)
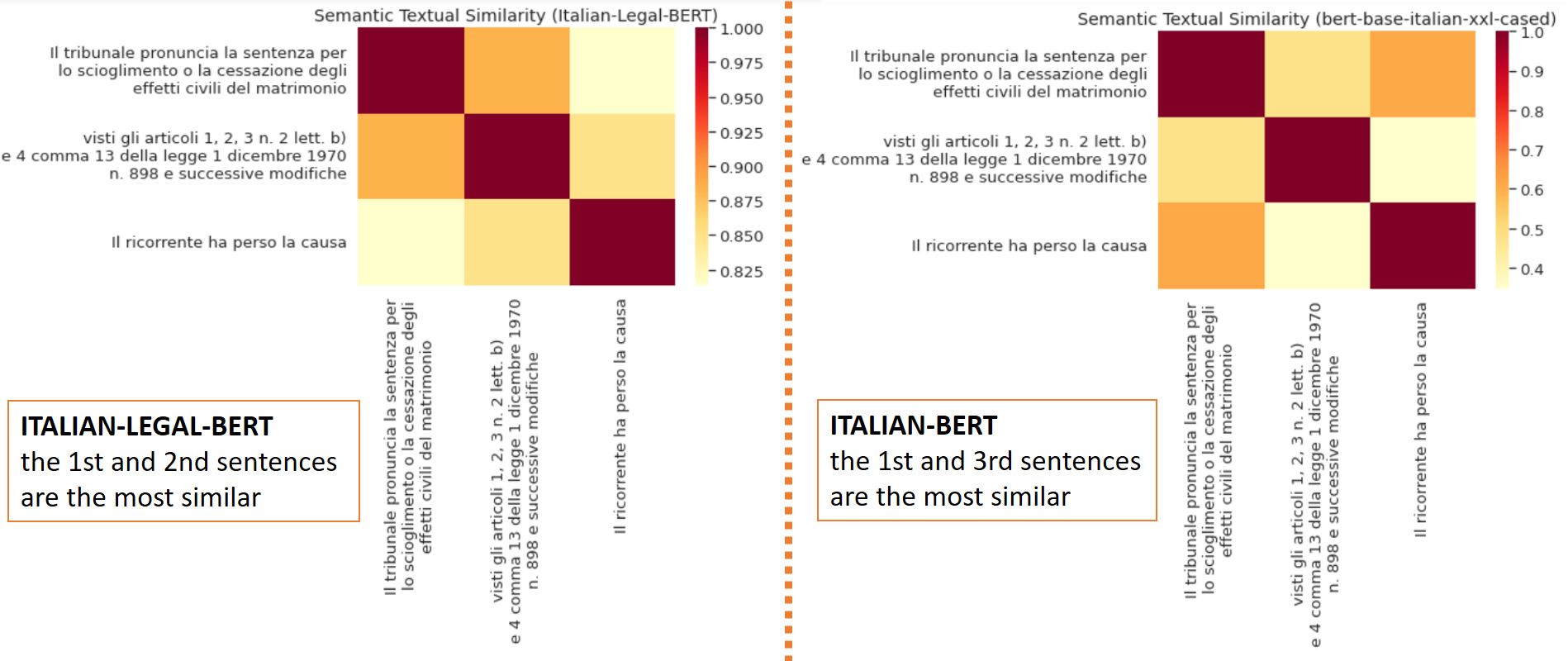
fill_mask("Il [MASK] ha chiesto revocarsi l'obbligo di pagamento")
#[{'sequence': "Il ricorrente ha chiesto revocarsi l'obbligo di pagamento",'score': 0.7264330387115479},
# {'sequence': "Il convenuto ha chiesto revocarsi l'obbligo di pagamento",'score': 0.09641049802303314},
# {'sequence': "Il resistente ha chiesto revocarsi l'obbligo di pagamento",'score': 0.039877112954854965},
# {'sequence': "Il lavoratore ha chiesto revocarsi l'obbligo di pagamento",'score': 0.028993653133511543},
# {'sequence': "Il Ministero ha chiesto revocarsi l'obbligo di pagamento", 'score': 0.025297977030277252}]
In this COLAB: ITALIAN-LEGAL-BERT: Minimal Start for Italian Legal Downstream Tasks how to use it for sentence similarity, sentence classification, and named entity recognition
Citation
If you find our resource or paper is useful, please consider including the following citation in your paper.@article{ita_legalbert_2022,
author = {Daniele Licari and Giovanni Comandè},
title = {ITALIAN-LEGAL-BERT: A Pre-trained Transformer
Language Model for Italian Law},
booktitle = {Proceedings of The Knowledge Management for Law Workshop (KM4LAW)}
note = {Accepted for publication},
year = {2022}
}