
ccmusic-database/erhu_playing_tech
Audio Classification
•
Updated
•
9
This dataset was created and has been utilized for Erhu playing technique detection by [1], which has not undergone peer review. The original dataset comprises 1,253 Erhu audio clips, all performed by professional Erhu players. These clips were annotated according to three hierarchical levels, resulting in annotations for four, seven, and 11 categories. Part of the audio data is sourced from the CTIS dataset described earlier.
We first perform label cleaning to abandon the labels for the four and seven categories, since they do not strictly form a hierarchical relationship, and there are also missing data problems. This process leaves us with only the labels for the 11 categories. Then, we add Chinese character label and Chinese pinyin label to enhance comprehensibility. The 11 labels are: Detache (分弓), Diangong (垫弓), Harmonic (泛音), Legato\slide\glissando (连弓\滑音\连音), Percussive (击弓), Pizzicato (拨弦), Ricochet (抛弓), Staccato (断弓), Tremolo (震音), Trill (颤音), and Vibrato (揉弦). After integration, the data structure contains six columns: audio (with a sampling rate of 44,100 Hz), mel spectrograms, numeric label, Italian label, Chinese character label, and Chinese pinyin label. The total number of audio clips remains at 1,253, with a total duration of 25.81 minutes. The average duration is 1.24 seconds.
We constructed the default subset of the current integrated version dataset based on its 11 classification data and optimized the names of the 11 categories. The data structure can be seen in the viewer. Although the original dataset has been cited in some articles, the experiments in those articles lack reproducibility. In order to demonstrate the effectiveness of the default subset, we further processed the data and constructed the eval subset to supplement the evaluation of this integrated version dataset. The results of the evaluation can be viewed in [2]. In addition, the labels of categories 4 and 7 in the original dataset were not discarded. Instead, they were separately constructed into 4_class subset and 7_class subset. However, these two subsets have not been evaluated and therefore are not reflected in our paper.
 |
 |
 |
 |
|---|---|---|---|
| Fig. 1 | Fig. 2 | Fig. 3 | Fig. 4 |
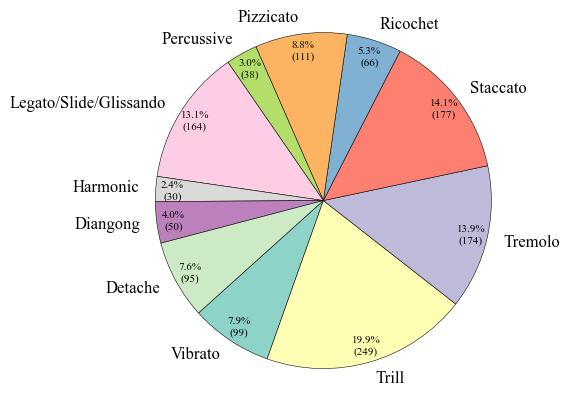
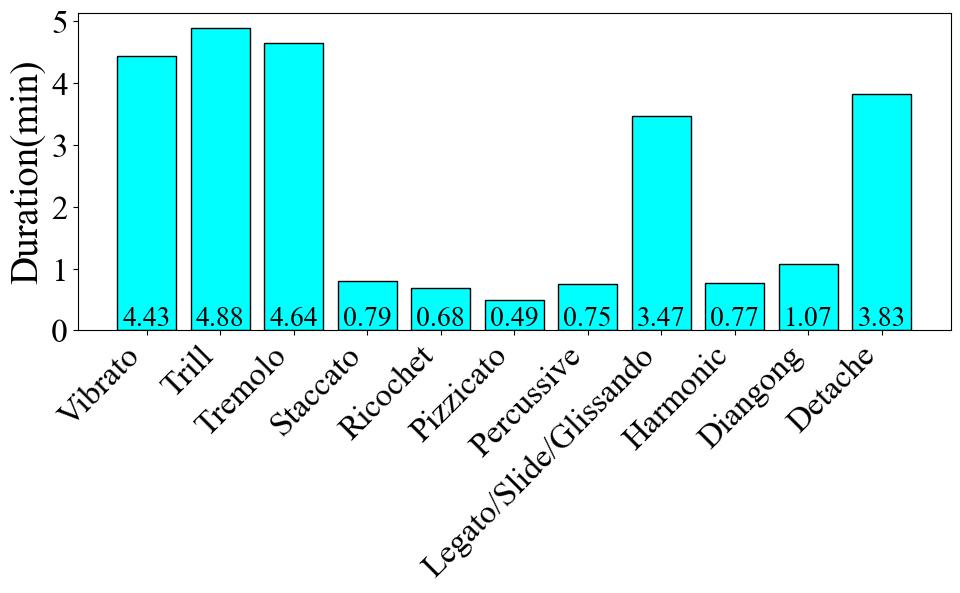
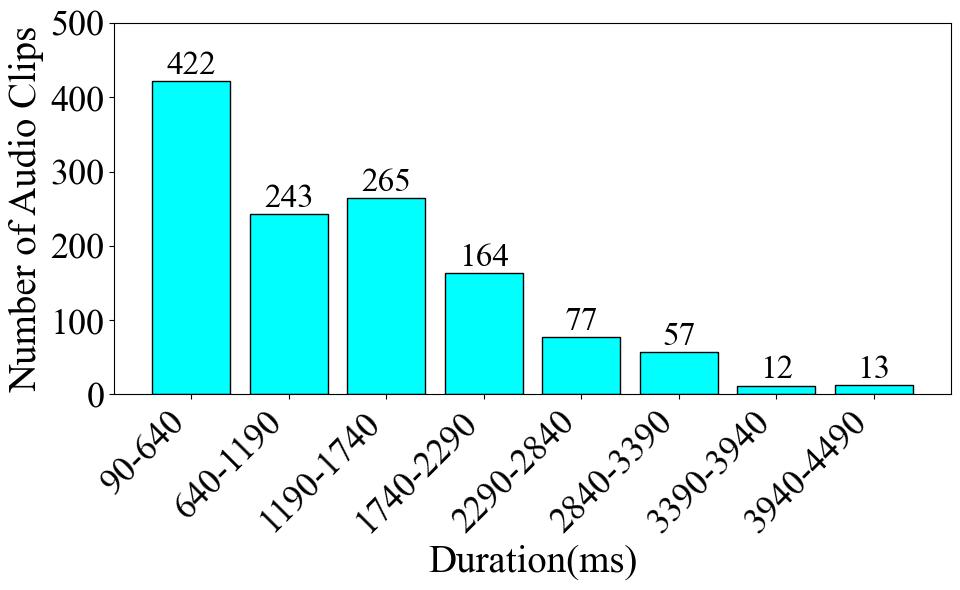
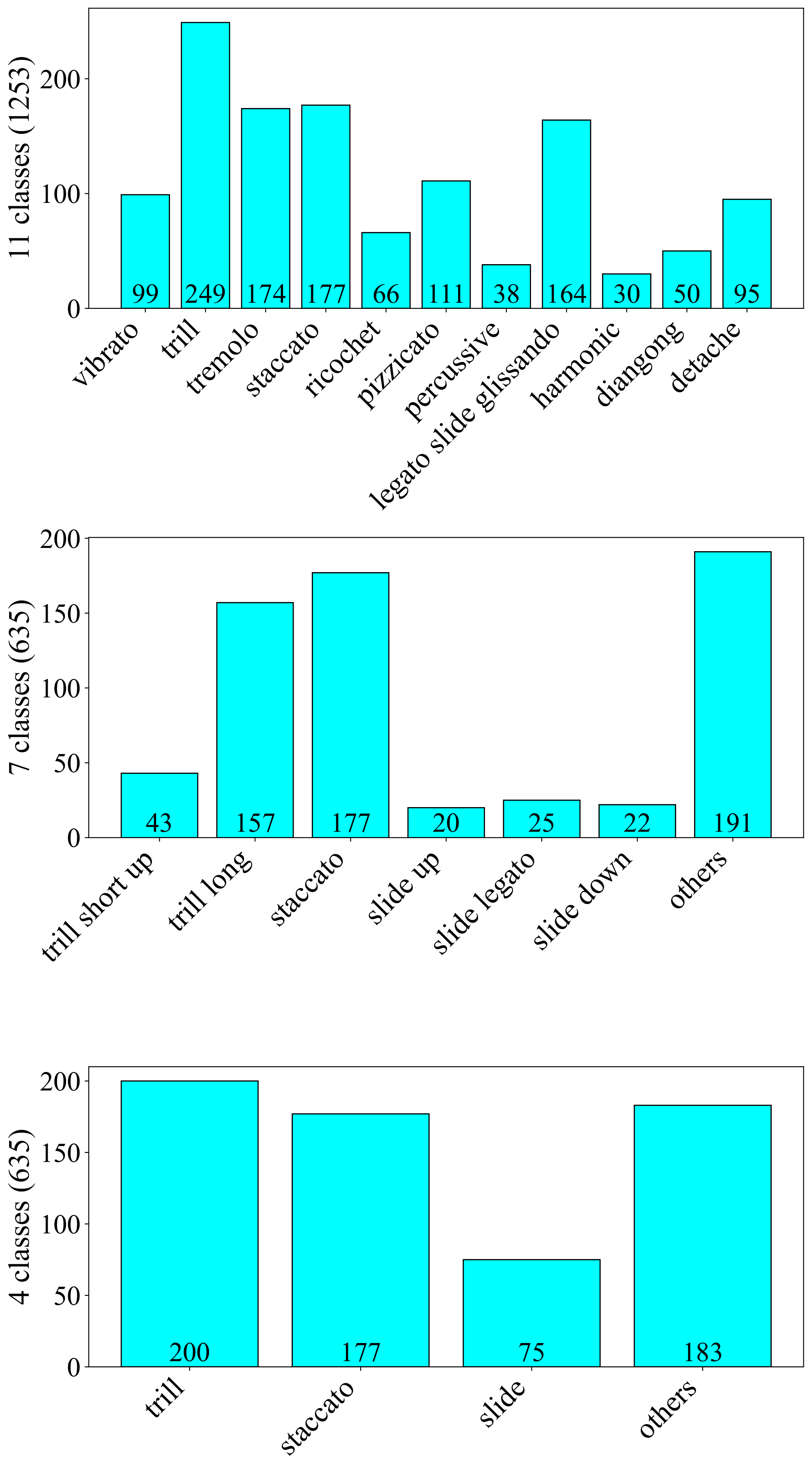
To begin with, Fig. 1 presents the number of data entries per label. The Trill label has the highest data volume, with 249 instances, which accounts for 19.9% of the total dataset. Conversely, the Harmonic label has the least amount of data, with only 30 instances, representing a meager 2.4% of the total. Turning to the audio duration per category, as illustrated in Fig. 2, the audio data associated with the Trill label has the longest cumulative duration, amounting to 4.88 minutes. In contrast, the Percussive label has the shortest audio duration, clocking in at 0.75 minutes. These disparities clearly indicate a class imbalance problem within the dataset. Finally, as shown in Fig. 3, we count the frequency of audio occurrences at 550-ms intervals. The quantity of data decreases as the duration lengthens. The most populated duration range is 90-640 ms, with 422 audio clips. The least populated range is 3390-3940 ms, which contains only 12 clips. Fig. 4 is the statistical charts for the 11_class (Default), 7_class, and 4_class subsets.
| Subset | Total count | Total duration(s) |
|---|---|---|
| Default / 11_classes / Eval | 1253 |
1548.3557823129247 |
| 7_classes / 4_classes | 635 |
719.8175736961448 |
| Statistical items | Values |
|---|---|
| Mean duration(ms) | 1235.7189004891661 |
| Min duration(ms) | 91.7687074829932 |
| Max duration(ms) | 4468.934240362812 |
| Classes in the longest audio duartion interval | Vibrato, Detache |
| audio | mel | label |
|---|---|---|
| .wav, 44100Hz | .jpg, 44100Hz | 4/7/11-class |
| mel | cqt | chroma | label |
|---|---|---|---|
| .jpg, 44100Hz | .jpg, 44100Hz | .jpg, 44100Hz | 11-class |
.zip(.wav, .jpg)
+ detache 分弓 (72)
+ forte (8)
+ medium (8)
+ piano (56)
+ diangong 垫弓 (28)
+ harmonic 泛音 (18)
+ natural 自然泛音 (6)
+ artificial 人工泛音 (12)
+ legato&slide&glissando 连弓&滑音&大滑音 (114)
+ glissando_down 大滑音 下行 (4)
+ glissando_up 大滑音 上行 (4)
+ huihuayin_down 下回滑音 (18)
+ huihuayin_long_down 后下回滑音 (12)
+ legato&slide_up 向上连弓 包含滑音 (24)
+ forte (8)
+ medium (8)
+ piano (8)
+ slide_dianzhi 垫指滑音 (4)
+ slide_down 向下滑音 (16)
+ slide_legato 连线滑音 (16)
+ slide_up 向上滑音 (16)
+ percussive 打击类音效 (21)
+ dajigong 大击弓 (11)
+ horse 马嘶 (2)
+ stick 敲击弓 (8)
+ pizzicato 拨弦 (96)
+ forte (30)
+ medium (29)
+ piano (30)
+ left 左手勾弦 (6)
+ ricochet 抛弓 (36)
+ staccato 顿弓 (141)
+ forte (47)
+ medium (46)
+ piano (48)
+ tremolo 颤弓 (144)
+ forte (48)
+ medium (48)
+ piano (48)
+ trill 颤音 (202)
+ long 长颤音 (141)
+ forte (46)
+ medium (47)
+ piano (48)
+ short 短颤音 (61)
+ down 下颤音 (30)
+ up 上颤音 (31)
+ vibrato 揉弦 (56)
+ late (13)
+ press 压揉 (6)
+ roll 滚揉 (28)
+ slide 滑揉 (9)
train, validation, test
The label system is hierarchical and contains three levels in the raw dataset. The first level consists of four categories: trill, staccato, slide, and others; the second level comprises seven categories: trill\short\up, trill\long, staccato, slide up, slide\legato, slide\down, and others; the third level consists of 11 categories, representing the 11 playing techniques described earlier. Although it also employs a three-level label system, the higher-level labels do not exhibit complete downward compatibility with the lower-level labels. Therefore, we cannot merge these three-level labels into the same split but must treat them as three separate subsets.
Erhu Playing Technique Classification
Chinese, English
from datasets import load_dataset
dataset = load_dataset("ccmusic-database/erhu_playing_tech", name="eval")
for item in ds["train"]:
print(item)
for item in ds["validation"]:
print(item)
for item in ds["test"]:
print(item)
from datasets import load_dataset
dataset = load_dataset("ccmusic-database/erhu_playing_tech", name="4_classes")
for item in ds["train"]:
print(item)
for item in ds["validation"]:
print(item)
for item in ds["test"]:
print(item)
from datasets import load_dataset
ds = load_dataset("ccmusic-database/erhu_playing_tech", name="7_classes")
for item in ds["train"]:
print(item)
for item in ds["validation"]:
print(item)
for item in ds["test"]:
print(item)
from datasets import load_dataset
# default subset
ds = load_dataset("ccmusic-database/erhu_playing_tech", name="11_classes")
for item in ds["train"]:
print(item)
for item in ds["validation"]:
print(item)
for item in ds["test"]:
print(item)
git clone [email protected]:datasets/ccmusic-database/erhu_playing_tech
cd erhu_playing_tech
Lack of a dataset for Erhu playing tech
Zhaorui Liu, Monan Zhou
Students from CCMUSIC
This dataset is an audio dataset containing 927 audio clips recorded by the China Conservatory of Music, each with a performance technique of erhu.
Students from CCMUSIC
Advancing the Digitization Process of Traditional Chinese Instruments
Only for Erhu
Not Specific Enough in Categorization
Zijin Li
[1] Wang, Zehao et al. “Musical Instrument Playing Technique Detection Based on FCN: Using Chinese Bowed-Stringed Instrument as an Example.” ArXiv abs/1910.09021 (2019): n. pag.
[2] https://huggingface.co/ccmusic-database/erhu_playing_tech
@dataset{zhaorui_liu_2021_5676893,
author = {Monan Zhou, Shenyang Xu, Zhaorui Liu, Zhaowen Wang, Feng Yu, Wei Li and Baoqiang Han},
title = {CCMusic: an Open and Diverse Database for Chinese Music Information Retrieval Research},
month = {mar},
year = {2024},
publisher = {HuggingFace},
version = {1.2},
url = {https://huggingface.co/ccmusic-database}
}
Provide a dataset for Erhu playing tech