
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,7 +1,6 @@
|
|
| 1 |
---
|
| 2 |
-
library_name: transformers
|
| 3 |
license: mit
|
| 4 |
-
base_model:
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
| 7 |
- full
|
|
@@ -10,8 +9,6 @@ tags:
|
|
| 10 |
- tiny
|
| 11 |
- chinese
|
| 12 |
- english
|
| 13 |
-
- llama-cpp
|
| 14 |
-
- gguf-my-repo
|
| 15 |
datasets:
|
| 16 |
- Chamoda/atlas-storyteller-1000
|
| 17 |
- jaydenccc/AI_Storyteller_Dataset
|
|
@@ -22,46 +19,37 @@ language:
|
|
| 22 |
pipeline_tag: text-generation
|
| 23 |
---
|
| 24 |
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
|
| 29 |
-
|
| 30 |
-
|
|
|
|
|
|
|
| 31 |
|
| 32 |
-
|
| 33 |
-
|
|
|
|
|
|
|
|
|
|
| 34 |
|
| 35 |
-
|
| 36 |
-
|
|
|
|
| 37 |
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
|
| 43 |
-
|
| 44 |
-
```bash
|
| 45 |
-
llama-server --hf-repo XeTute/Phantasor_V0.1-137M-Q8_0-GGUF --hf-file phantasor_v0.1-137m-q8_0.gguf -c 2048
|
| 46 |
-
```
|
| 47 |
|
| 48 |
-
|
|
|
|
|
|
|
| 49 |
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
git clone https://github.com/ggerganov/llama.cpp
|
| 53 |
-
```
|
| 54 |
|
| 55 |
-
|
| 56 |
-
```
|
| 57 |
-
cd llama.cpp && LLAMA_CURL=1 make
|
| 58 |
-
```
|
| 59 |
-
|
| 60 |
-
Step 3: Run inference through the main binary.
|
| 61 |
-
```
|
| 62 |
-
./llama-cli --hf-repo XeTute/Phantasor_V0.1-137M-Q8_0-GGUF --hf-file phantasor_v0.1-137m-q8_0.gguf -p "The meaning to life and the universe is"
|
| 63 |
-
```
|
| 64 |
-
or
|
| 65 |
-
```
|
| 66 |
-
./llama-server --hf-repo XeTute/Phantasor_V0.1-137M-Q8_0-GGUF --hf-file phantasor_v0.1-137m-q8_0.gguf -c 2048
|
| 67 |
-
```
|
|
|
|
| 1 |
---
|
|
|
|
| 2 |
license: mit
|
| 3 |
+
base_model: openai-community/gpt2
|
| 4 |
tags:
|
| 5 |
- llama-factory
|
| 6 |
- full
|
|
|
|
| 9 |
- tiny
|
| 10 |
- chinese
|
| 11 |
- english
|
|
|
|
|
|
|
| 12 |
datasets:
|
| 13 |
- Chamoda/atlas-storyteller-1000
|
| 14 |
- jaydenccc/AI_Storyteller_Dataset
|
|
|
|
| 19 |
pipeline_tag: text-generation
|
| 20 |
---
|
| 21 |
|
| 22 |
+
> [!TIP]
|
| 23 |
+
> Model is still in its testing phase. We don't recommend it for high-end production enviroments, it's only a model for story-generation.
|
| 24 |
+
> Model trained using LLaMA-Factory by Asadullah Hamzah at XeTute Technologies.
|
| 25 |
|
| 26 |
+
# Phantasor V0.1
|
| 27 |
+
We introduce Phantasor V0.1, our first sub-1B Parameter GPT. It has been trained ontop of GPT2's smallest version using a little bit over 1.5B input tokens.
|
| 28 |
+
Licensed under MIT, feel free to use it in your personal projects, both commercially and privately, Since this is V0.1, we're open to feedback to improve our project(s). **The Chat-Template used is Alpaca (### Instruction [...]).**
|
| 29 |
+
[You can find the FP32 version here.](https://huggingface.co/XeTute/Phantasor_V0.1-137M)
|
| 30 |
|
| 31 |
+
## Training
|
| 32 |
+
This model was trained on all samples, tokens included in:
|
| 33 |
+
- [Chamoda/atlas-storyteller-1000](https://huggingface.co/datasets/Chamoda/atlas-storyteller-1000)
|
| 34 |
+
- [jaydenccc/AI_Storyteller_Dataset](https://huggingface.co/datasets/jaydenccc/AI_Storyteller_Dataset)
|
| 35 |
+
- [zxbsmk/webnovel_cn](https://huggingface.co/datasets/zxbsmk/webnovel_cn)
|
| 36 |
|
| 37 |
+
for exactly 3.0 epochs on all model parameters. Following is the loss curve, updated with each training step over all three epochs.
|
| 38 |
+
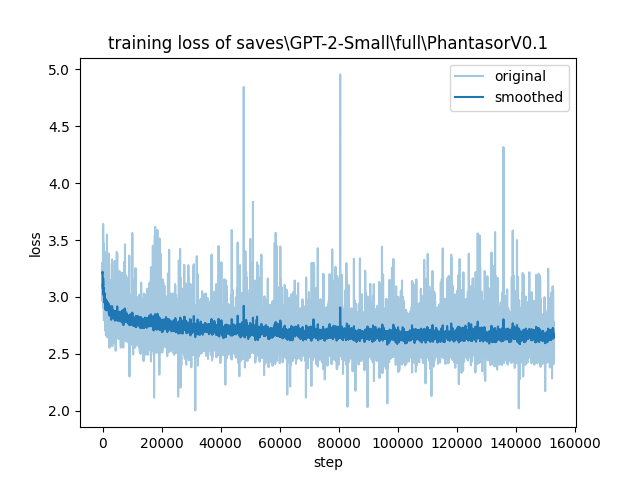
|
| 39 |
+
Instead of AdamW, which is often used for large GPTs, we used **SGD**, which enabled the model to generalize better, which can be seen when using the model on non-dataset prompts.
|
| 40 |
|
| 41 |
+
## Finished Model
|
| 42 |
+
- ~137M Parameters, all of which are trainable
|
| 43 |
+
- 1024 / 1k input tokens / context length, from which all were used
|
| 44 |
+
- A loss 2.2 on all samples
|
| 45 |
|
| 46 |
+
This is solid performance for a model with only 137M parameters.
|
|
|
|
|
|
|
|
|
|
| 47 |
|
| 48 |
+
# Our platforms
|
| 49 |
+
## Socials
|
| 50 |
+
[BlueSky](https://bsky.app/profile/xetute.bsky.social) | [YouTube](https://www.youtube.com/@XeTuteTechnologies) | [HuggingFace 🤗](https://huggingface.co/XeTute) | [Ko-Fi / Financially Support Us](https://ko-fi.com/XeTute)
|
| 51 |
|
| 52 |
+
## Our Platforms
|
| 53 |
+
[Our Webpage](https://xetute.com) | [PhantasiaAI](https://xetute.com/PhantasiaAI)
|
|
|
|
|
|
|
| 54 |
|
| 55 |
+
Have a great day!
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|