
Your Name
commited on
Commit
·
dc7373a
1
Parent(s):
fa69820
update
Browse files- .gitattributes +1 -0
- README copy.md +60 -0
- all_results.json +3 -0
- config.json +3 -0
- generation_config.json +3 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +3 -0
- special_tokens_map.json +3 -0
- tokenizer.json +3 -0
- tokenizer_config.json +3 -0
- train_results.json +3 -0
- trainer_log.jsonl +24 -0
- trainer_state.json +3 -0
- training_args.bin +3 -0
- training_loss.png +0 -0
- training_rewards_accuracies.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.json filter=lfs diff=lfs merge=lfs -text
|
README copy.md
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
license: other
|
| 4 |
+
base_model: saves/Llama-3.1-8B/full/train_sft_cot_mix-3
|
| 5 |
+
tags:
|
| 6 |
+
- llama-factory
|
| 7 |
+
- full
|
| 8 |
+
- generated_from_trainer
|
| 9 |
+
model-index:
|
| 10 |
+
- name: GuardReasoner 8B
|
| 11 |
+
results: []
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 15 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 16 |
+
|
| 17 |
+
# GuardReasoner 8B
|
| 18 |
+
|
| 19 |
+
This model is a fine-tuned version of [saves/Llama-3.1-8B/full/train_sft_cot_mix-3](https://huggingface.co/saves/Llama-3.1-8B/full/train_sft_cot_mix-3) on the 4_1_WildGuardTrainCotDpoSelf8BMix3Weight, the 4_2_AegisTrainCotDpoSelf8BMix248Weight, the 4_3_BeaverTailsTrainCotDpoSelf8BMix248Weight and the 4_4_ToxicChatTrainCotDpoSelf8BMix248Weight datasets.
|
| 20 |
+
|
| 21 |
+
## Model description
|
| 22 |
+
|
| 23 |
+
More information needed
|
| 24 |
+
|
| 25 |
+
## Intended uses & limitations
|
| 26 |
+
|
| 27 |
+
More information needed
|
| 28 |
+
|
| 29 |
+
## Training and evaluation data
|
| 30 |
+
|
| 31 |
+
More information needed
|
| 32 |
+
|
| 33 |
+
## Training procedure
|
| 34 |
+
|
| 35 |
+
### Training hyperparameters
|
| 36 |
+
|
| 37 |
+
The following hyperparameters were used during training:
|
| 38 |
+
- learning_rate: 5e-06
|
| 39 |
+
- train_batch_size: 1
|
| 40 |
+
- eval_batch_size: 8
|
| 41 |
+
- seed: 42
|
| 42 |
+
- distributed_type: multi-GPU
|
| 43 |
+
- num_devices: 4
|
| 44 |
+
- gradient_accumulation_steps: 64
|
| 45 |
+
- total_train_batch_size: 256
|
| 46 |
+
- total_eval_batch_size: 32
|
| 47 |
+
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 48 |
+
- lr_scheduler_type: cosine
|
| 49 |
+
- num_epochs: 2.0
|
| 50 |
+
|
| 51 |
+
### Training results
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
### Framework versions
|
| 56 |
+
|
| 57 |
+
- Transformers 4.46.1
|
| 58 |
+
- Pytorch 2.5.1+cu124
|
| 59 |
+
- Datasets 3.1.0
|
| 60 |
+
- Tokenizers 0.20.3
|
all_results.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a5bd846a2aabcf83f23a6ddcde02b39cc22e28a16c55d89bcac23941bd490e6e
|
| 3 |
+
size 255
|
config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1eab22225f06919595e4615317a2ad8b246845d6f404c8458349c461cbe1d4f3
|
| 3 |
+
size 907
|
generation_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e6bd0b30e743618c41de600b71fe491ba7060cd6f728d737371e55c6cd544352
|
| 3 |
+
size 180
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fcfe333fd7c47f62a9b83d7c5b4f6ebd4a6e39e1af104ce948ee285dd3806efe
|
| 3 |
+
size 4976698672
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0fda3b2a5179348473559faefc3803d9188257481f2d20e98d2d41d980736083
|
| 3 |
+
size 4999802720
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9098c58ba0b52b1d13bc2a7ef61b152fb49f9d235b93b0015cfe8ebe63f5a691
|
| 3 |
+
size 4915916176
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4bf5cb1a089236bd4801411a079f29842242008579483336e11d325d904ef2b4
|
| 3 |
+
size 1168138808
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:146776fce3f6db1103aa6f249e65ee5544c5923ce6f971b092eee79aa6e5d37b
|
| 3 |
+
size 23950
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:208d307467cabecb563e033fdb478b7c11a1bc6eca9a9c761bf6a303ccfce4c1
|
| 3 |
+
size 439
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6b9e4e7fb171f92fd137b777cc2714bf87d11576700a1dcd7a399e7bbe39537b
|
| 3 |
+
size 17209920
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fdd2ab776c0ad7171e4ba6ed31aba7c04843bc531da2875d91f49b35db660f4a
|
| 3 |
+
size 51269
|
train_results.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a5bd846a2aabcf83f23a6ddcde02b39cc22e28a16c55d89bcac23941bd490e6e
|
| 3 |
+
size 255
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
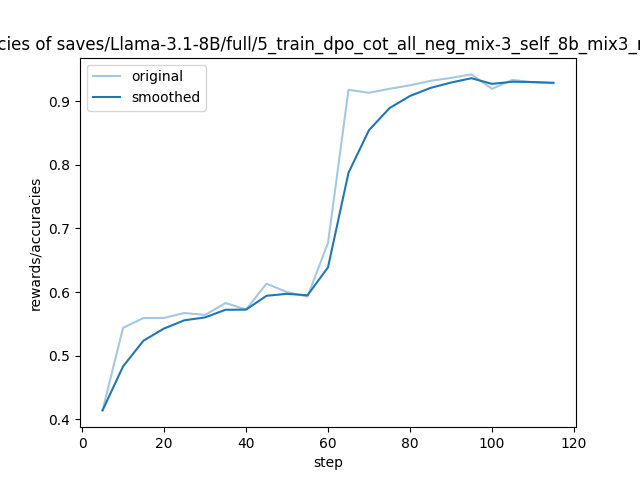
| 1 |
+
{"current_steps": 5, "total_steps": 116, "loss": 0.9374, "accuracy": 0.4140625, "lr": 4.977113991447017e-06, "epoch": 0.08528784648187633, "percentage": 4.31, "elapsed_time": "0:03:56", "remaining_time": "1:27:22", "throughput": 6798.66, "total_tokens": 1605552}
|
| 2 |
+
{"current_steps": 10, "total_steps": 116, "loss": 0.9242, "accuracy": 0.5437500476837158, "lr": 4.908874981298058e-06, "epoch": 0.17057569296375266, "percentage": 8.62, "elapsed_time": "0:07:31", "remaining_time": "1:19:45", "throughput": 7125.39, "total_tokens": 3216720}
|
| 3 |
+
{"current_steps": 15, "total_steps": 116, "loss": 0.9267, "accuracy": 0.559374988079071, "lr": 4.796532344409055e-06, "epoch": 0.255863539445629, "percentage": 12.93, "elapsed_time": "0:11:05", "remaining_time": "1:14:40", "throughput": 7182.43, "total_tokens": 4779104}
|
| 4 |
+
{"current_steps": 20, "total_steps": 116, "loss": 0.8918, "accuracy": 0.559374988079071, "lr": 4.642142940418973e-06, "epoch": 0.3411513859275053, "percentage": 17.24, "elapsed_time": "0:14:40", "remaining_time": "1:10:25", "throughput": 7237.67, "total_tokens": 6370944}
|
| 5 |
+
{"current_steps": 25, "total_steps": 116, "loss": 0.8981, "accuracy": 0.567187488079071, "lr": 4.448533455103979e-06, "epoch": 0.42643923240938164, "percentage": 21.55, "elapsed_time": "0:18:15", "remaining_time": "1:06:28", "throughput": 7263.65, "total_tokens": 7959680}
|
| 6 |
+
{"current_steps": 30, "total_steps": 116, "loss": 0.8772, "accuracy": 0.5640624761581421, "lr": 4.219248647133559e-06, "epoch": 0.511727078891258, "percentage": 25.86, "elapsed_time": "0:21:54", "remaining_time": "1:02:46", "throughput": 7246.56, "total_tokens": 9522352}
|
| 7 |
+
{"current_steps": 35, "total_steps": 116, "loss": 0.898, "accuracy": 0.582812488079071, "lr": 3.958486447768736e-06, "epoch": 0.5970149253731343, "percentage": 30.17, "elapsed_time": "0:25:24", "remaining_time": "0:58:48", "throughput": 7275.82, "total_tokens": 11093456}
|
| 8 |
+
{"current_steps": 40, "total_steps": 116, "loss": 0.8882, "accuracy": 0.5726562738418579, "lr": 3.671021101749476e-06, "epoch": 0.6823027718550106, "percentage": 34.48, "elapsed_time": "0:28:56", "remaining_time": "0:55:00", "throughput": 7312.81, "total_tokens": 12701344}
|
| 9 |
+
{"current_steps": 45, "total_steps": 116, "loss": 0.8784, "accuracy": 0.61328125, "lr": 3.3621157565699265e-06, "epoch": 0.767590618336887, "percentage": 38.79, "elapsed_time": "0:32:27", "remaining_time": "0:51:12", "throughput": 7342.31, "total_tokens": 14296512}
|
| 10 |
+
{"current_steps": 50, "total_steps": 116, "loss": 0.9261, "accuracy": 0.6000000238418579, "lr": 3.0374261005275606e-06, "epoch": 0.8528784648187633, "percentage": 43.1, "elapsed_time": "0:36:02", "remaining_time": "0:47:34", "throughput": 7365.95, "total_tokens": 15928592}
|
| 11 |
+
{"current_steps": 55, "total_steps": 116, "loss": 0.9059, "accuracy": 0.592968761920929, "lr": 2.7028968138185783e-06, "epoch": 0.9381663113006397, "percentage": 47.41, "elapsed_time": "0:39:30", "remaining_time": "0:43:48", "throughput": 7391.93, "total_tokens": 17519168}
|
| 12 |
+
{"current_steps": 60, "total_steps": 116, "loss": 0.8179, "accuracy": 0.6773437261581421, "lr": 2.3646527285364565e-06, "epoch": 1.0258528784648187, "percentage": 51.72, "elapsed_time": "0:43:03", "remaining_time": "0:40:11", "throughput": 7403.87, "total_tokens": 19125984}
|
| 13 |
+
{"current_steps": 65, "total_steps": 116, "loss": 0.6746, "accuracy": 0.91796875, "lr": 2.0288866903042055e-06, "epoch": 1.1111407249466951, "percentage": 56.03, "elapsed_time": "0:46:32", "remaining_time": "0:36:31", "throughput": 7410.99, "total_tokens": 20697888}
|
| 14 |
+
{"current_steps": 70, "total_steps": 116, "loss": 0.628, "accuracy": 0.913281261920929, "lr": 1.7017461746600506e-06, "epoch": 1.1964285714285714, "percentage": 60.34, "elapsed_time": "0:49:59", "remaining_time": "0:32:51", "throughput": 7423.13, "total_tokens": 22266688}
|
| 15 |
+
{"current_steps": 75, "total_steps": 116, "loss": 0.6339, "accuracy": 0.9195312261581421, "lr": 1.3892207341152416e-06, "epoch": 1.2817164179104479, "percentage": 64.66, "elapsed_time": "0:53:32", "remaining_time": "0:29:16", "throughput": 7430.42, "total_tokens": 23871248}
|
| 16 |
+
{"current_steps": 80, "total_steps": 116, "loss": 0.5881, "accuracy": 0.925000011920929, "lr": 1.0970323365940443e-06, "epoch": 1.3670042643923241, "percentage": 68.97, "elapsed_time": "0:57:07", "remaining_time": "0:25:42", "throughput": 7430.5, "total_tokens": 25468848}
|
| 17 |
+
{"current_steps": 85, "total_steps": 116, "loss": 0.6033, "accuracy": 0.9320312738418579, "lr": 8.305306030282618e-07, "epoch": 1.4522921108742004, "percentage": 73.28, "elapsed_time": "1:00:35", "remaining_time": "0:22:05", "throughput": 7447.9, "total_tokens": 27076896}
|
| 18 |
+
{"current_steps": 90, "total_steps": 116, "loss": 0.589, "accuracy": 0.9367187023162842, "lr": 5.945948621809092e-07, "epoch": 1.5375799573560767, "percentage": 77.59, "elapsed_time": "1:04:06", "remaining_time": "0:18:31", "throughput": 7452.28, "total_tokens": 28664544}
|
| 19 |
+
{"current_steps": 95, "total_steps": 116, "loss": 0.6067, "accuracy": 0.9421875476837158, "lr": 3.935448159583774e-07, "epoch": 1.622867803837953, "percentage": 81.9, "elapsed_time": "1:07:38", "remaining_time": "0:14:57", "throughput": 7460.21, "total_tokens": 30277808}
|
| 20 |
+
{"current_steps": 100, "total_steps": 116, "loss": 0.5691, "accuracy": 0.9195312857627869, "lr": 2.3106145082260777e-07, "epoch": 1.7081556503198294, "percentage": 86.21, "elapsed_time": "1:11:05", "remaining_time": "0:11:22", "throughput": 7466.48, "total_tokens": 31851152}
|
| 21 |
+
{"current_steps": 105, "total_steps": 116, "loss": 0.6039, "accuracy": 0.93359375, "lr": 1.1011964332097114e-07, "epoch": 1.793443496801706, "percentage": 90.52, "elapsed_time": "1:14:38", "remaining_time": "0:07:49", "throughput": 7470.46, "total_tokens": 33459936}
|
| 22 |
+
{"current_steps": 110, "total_steps": 116, "loss": 0.5714, "accuracy": 0.9296875, "lr": 3.293369364618465e-08, "epoch": 1.8787313432835822, "percentage": 94.83, "elapsed_time": "1:18:11", "remaining_time": "0:04:15", "throughput": 7476.11, "total_tokens": 35074912}
|
| 23 |
+
{"current_steps": 115, "total_steps": 116, "loss": 0.6022, "accuracy": 0.9281250238418579, "lr": 9.167844417901084e-10, "epoch": 1.9640191897654584, "percentage": 99.14, "elapsed_time": "1:21:44", "remaining_time": "0:00:42", "throughput": 7474.63, "total_tokens": 36659616}
|
| 24 |
+
{"current_steps": 116, "total_steps": 116, "epoch": 1.9810767590618337, "percentage": 100.0, "elapsed_time": "1:22:57", "remaining_time": "0:00:00", "throughput": 7427.48, "total_tokens": 36969776}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:995948a18ac4d34528e8e6cb083257cb1bf1eb78787b648f116448210fbdf67f
|
| 3 |
+
size 14255
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a350938375d1987f45f0c9135a1b6a13a716df9d000f9546b3078ab9be70a2c7
|
| 3 |
+
size 7288
|
training_loss.png
ADDED

|
training_rewards_accuracies.png
ADDED
|