
Update README.md
Browse files
README.md
CHANGED
|
@@ -20,10 +20,12 @@ metrics:
|
|
| 20 |

|
| 21 |
---
|
| 22 |
|
| 23 |
-
> [!TIP] With no regressions, mostly gains over the previous release, this version of Lamarck has [broken the 41.0 average](https://shorturl.at/jUqEk) maximum for 14B parameter models. As of this writing, Lamarck v0.7 ranks #8 among models under 70B parameters on the Open LLM Leaderboard. Given the quality models in the 32B range, I think Lamarck deserves his shades. A little layer analysis of a model in the 14B range goes a long, long way.
|
| 24 |
|
| 25 |
> [!TIP] The first DPO finetune of Lamarck has appeared! Check out [jpacifico/Chocolatine-2-14B-Instruct-v2.0b3](http://huggingface.co/jpacifico/Chocolatine-2-14B-Instruct-v2.0b3), whose notes say, "The Chocolatine model series is a quick demonstration that a base model can be easily fine-tuned to achieve compelling performance." Lamarck's painstaking merge process was intended to make finetuning to a desired polish as easy and energy-efficient as possible. Thank you, @jpacifico!
|
| 26 |
|
|
|
|
|
|
|
| 27 |
Lamarck 14B v0.7: A generalist merge with emphasis on multi-step reasoning, prose, and multi-language ability. The 14B parameter model class has a lot of strong performers, and Lamarck strives to be well-rounded and solid: 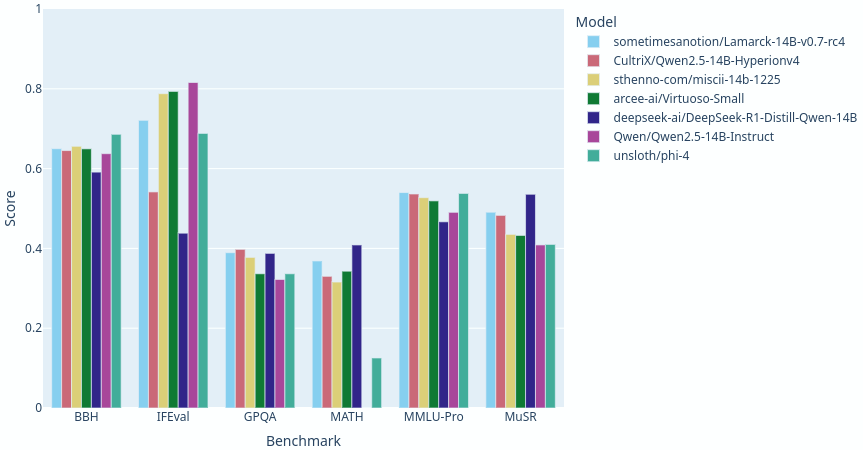
|
| 28 |
|
| 29 |
Lamarck is produced by a custom toolchain to automate a complex sequences of LoRAs and various layer-targeting merges:
|
|
|
|
| 20 |

|
| 21 |
---
|
| 22 |
|
| 23 |
+
> [!TIP] With no benchmark regressions, mostly gains over the previous release, this version of Lamarck has [broken the 41.0 average](https://shorturl.at/jUqEk) maximum for 14B parameter models. As of this writing, Lamarck v0.7 ranks #8 among models under 70B parameters on the Open LLM Leaderboard. Given the quality models in the 32B range, I think Lamarck deserves his shades. A little layer analysis of a model in the 14B range goes a long, long way.
|
| 24 |
|
| 25 |
> [!TIP] The first DPO finetune of Lamarck has appeared! Check out [jpacifico/Chocolatine-2-14B-Instruct-v2.0b3](http://huggingface.co/jpacifico/Chocolatine-2-14B-Instruct-v2.0b3), whose notes say, "The Chocolatine model series is a quick demonstration that a base model can be easily fine-tuned to achieve compelling performance." Lamarck's painstaking merge process was intended to make finetuning to a desired polish as easy and energy-efficient as possible. Thank you, @jpacifico!
|
| 26 |
|
| 27 |
+
> [!TIP] Those providing feedback, thank you! As Lamarck v0.7 has two varieties of chain-of-thought in its ancestry, it has both high reasoning potential for its class, and some volatility in step-by-step use cases. For those needing more stability with <think> tags, [Lamarck 0.6](https://huggingface.co/sometimesanotion/Lamarck-14B-v0.6) uses CoT more sparingly, and Chocolatine is gratifyingly stable.
|
| 28 |
+
|
| 29 |
Lamarck 14B v0.7: A generalist merge with emphasis on multi-step reasoning, prose, and multi-language ability. The 14B parameter model class has a lot of strong performers, and Lamarck strives to be well-rounded and solid: 
|
| 30 |
|
| 31 |
Lamarck is produced by a custom toolchain to automate a complex sequences of LoRAs and various layer-targeting merges:
|